Curbing Strategic Deception in Digital Markets¶
Swapneel Mehta$^{1,2}$, Aaron Nichols$^2$, Nina Mazar$^2$, Marshall Van Alstyne$^2$
$^1$ MIT $^2$ Boston University
Aaron Nichols: experimental economics, incentive design. Nina Mazar: behavioral science of honesty, consumer decisions, formerly World Bank. Marshall Van Alstyne: platform economics, two-sided markets.About Me¶
- Ph.D. in Data Science, New York University
- Postdoc at MIT and Boston University on AI Safety in Information Markets
- Previously built ML systems at X, Slack, Adobe, Oxford, Meta, CERN
- Co-founded SimPPL (2021), nonprofit research lab working in 7 countries, $2.5M+ in grants from Google, Mozilla, Wikimedia, Ford, Omidyar
How can we improve reliability of AI-mediated information?¶
- Curb deception to improve reliability: How do we reduce agentic deception on digital platforms? (TODAY'S TALK)
- Build inclusive solutions: How do we deliver accurate health information in the global south?
- User controls for value creation: Can user controls improve value creation on decentralized platforms?
- Make information ecosystems transparent: Can we surface digital harms with investigative AI agents?
Agentic AI deceives in competitive settings¶
- AI discovers insider trading when tasked with profit maximization (Scheurer et al., 2024)
- AI pretends to collaborate then exploits partners in Diplomacy (Meta CICERO, Science 2022)
- LLM pricing agents autonomously reach supracompetitive prices (Fish et al., 2024)
AI is the new third-party seller¶


No one has studied what happens when AI sellers compete with human buyers under different governance regimes. That is the gap.
Reputation systems rest on violated assumptions¶
- Long-lived entities who care about future interactions. But sellers rebrand costlessly. (Friedman & Resnick, 2001)
- Feedback is honest and informative. But fake reviews manipulate ratings, making them unreliable signals of quality. (Tadelis, 2016; Mayzlin et al., 2014)
- Rated entities are human decision-makers. AI agents can process feedback and optimize strategies at scales impossible for humans, including strategic market exits. (Cabral & Hortacsu, 2010)
Amazon spends $1.2B and still can't stop it¶



275 million suspected fake reviews blocked in 2024. 15 million counterfeits seized. Sellers openly trade accounts on Reddit.
How can we avoid agents deceiving human buyers in digital marketplaces?¶
Can market design govern AI behavior through incentive alignment, without modifying the AI itself?
Staking builds on costly signaling theory¶
- Information asymmetry causes adverse selection: low-quality goods drive out high-quality when buyers cannot distinguish quality (Akerlof, 1970)
- Costly signals resolve this: signals are credible because they are differentially expensive to fake (Spence, 1973)
- Our prior work tested "truth warrants" for social media sharing. Across 3 experiments (N=5,277), warrants increased sharing quality and perceived accuracy without censorship (Nichols, Mazar, Mehta, Parker, Pennycook, Rand, Van Alstyne; R&R at Nature Communications)
- This paper extends truth warrants from information markets to product markets, and from human sharers to AI agent sellers
Community governance scales for disputes¶

- X's Community Notes reduce retweets by ~50%, increase deletions by 80% (Renault et al., 2024). But notes arrive after ~80% of engagement has occurred.
- Taobao peer juries: 4 million volunteers adjudicate 2,000+ disputes per day since 2012
- Meituan user juries: 6 million registered jurors for food delivery disputes
- Staking moves adjudication to pre-sale: the signal happens before purchase, not after
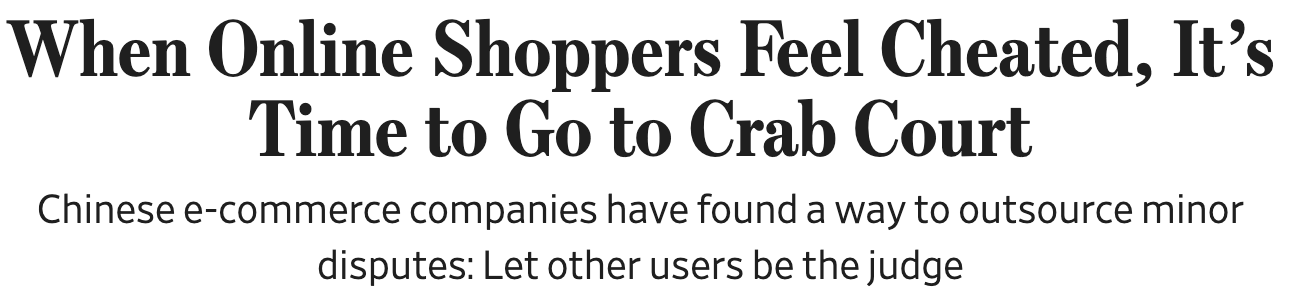
Improving accountability via staking¶
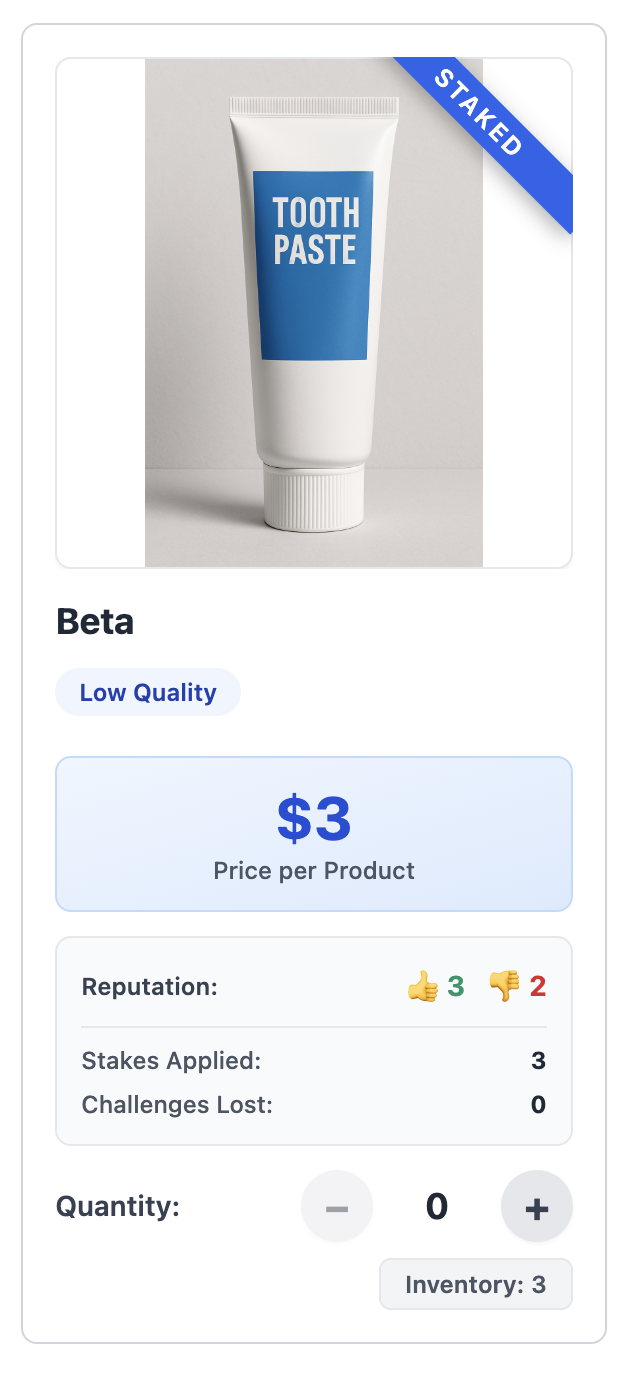
Without stake
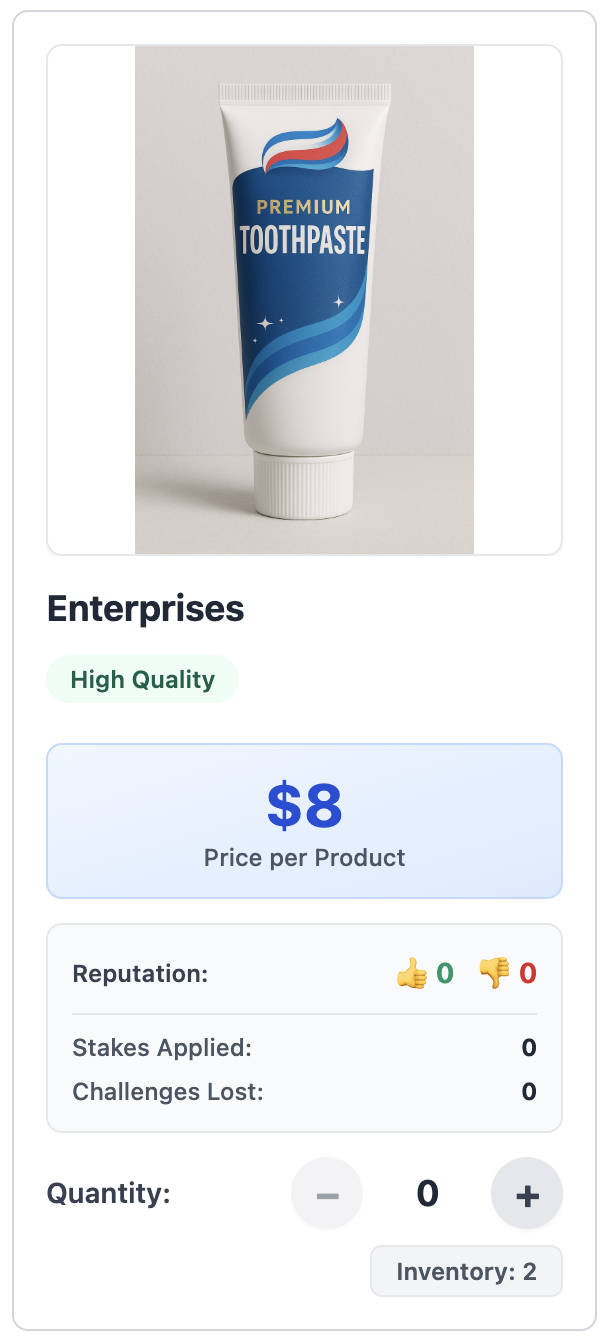
With stake
- Current markets rely on reputation (thumbs up/down)
- Staking = seller escrows extra collateral to back advertised claims
- If claim is false and buyer challenges successfully, collateral is forfeited
- Staked products carry an "integrity premium" (higher price to buyer)
Sellers voluntarily stake to signal honesty¶
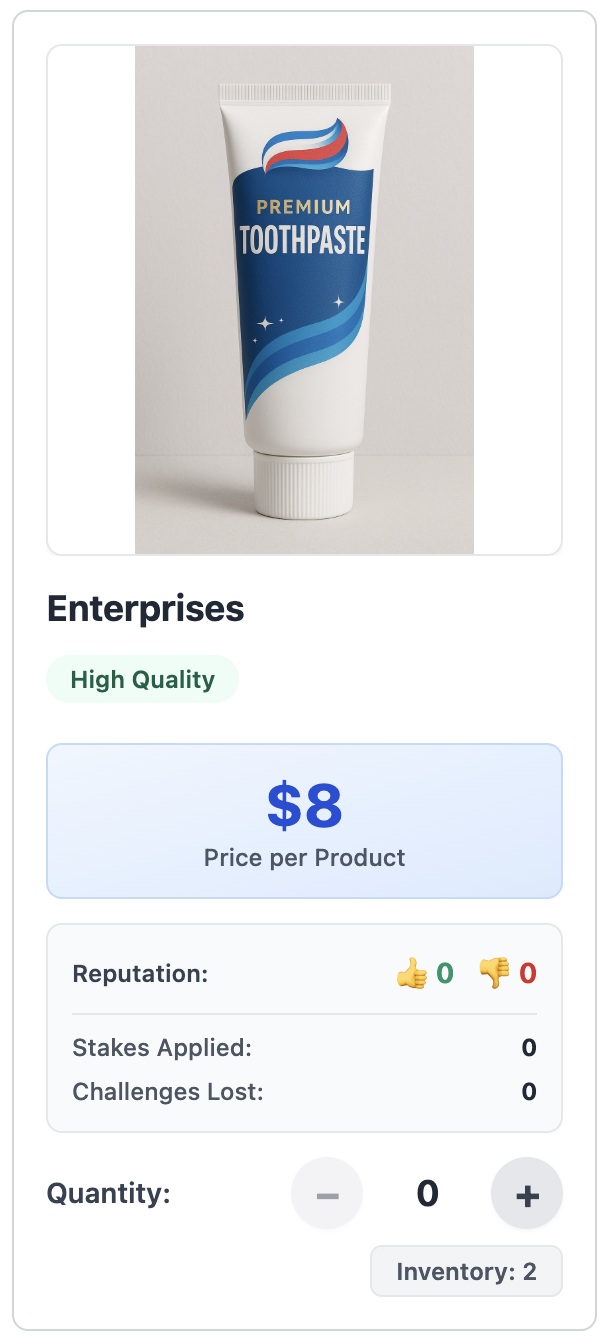
- Sellers deposit money to "stake" their product advertisements
- Staking places a refundable amount at risk. If unchallenged or honest, seller gets it back.
- If the ad is false and a buyer challenges it, the stake is forfeited to the buyer
- The warrant is voluntary and self-imposed. Honest sellers use it as a differentiator.
We need experiments that reflect real markets¶
How to run controlled experiments that reflect interactive, long-horizon,
utility-maximizing decision-making in real marketplaces?
Build an online marketplace. No open benchmarks exist for AI sellers in two-sided markets. Our platform is the first with real-time human-AI experimentation.
See the marketplace in action¶
Seller experience
Buyer experience
Reputation Market: Basic Flow¶
or dishonest ads
products to buy
points awarded to buyers
based on products sold
Reputation Market: Identity Reset¶
ads
choose
revealed
profits
for false sales
to reset reputation
Stakes Market: Pre-Sale Accountability¶
May stake to signal honesty.
products to buy
revealed to buyers
based on products sold
Stakes Market: Buyer Recourse¶
+ optional stake
choose
revealed
profits
staked ads to win back points
false stakes (lost challenges)
to reset staking history
Seller Choices and Profit Maximization¶
→ Add Stake (+2) or No Stake
→ Add Stake (-9 if challenged) or No Stake
Buyer Choices and Profit Maximization¶
→ Low Quality Product (-4, cheated)
→ Low Quality Product (+1)
Seven Seller Strategies from Axelrod (1981)¶
| # | Strategy | Production | Advertising |
|---|---|---|---|
| 1 | Honest | Always high quality | Honest |
| 2 | Bait-and-Switch | High until sold, then switch | Dishonest after switch |
| 3 | Cheater | Always low quality | Always dishonest |
| 4 | Reformed Cheat | Low until sold, then high | Switches |
| 5 | Goldfish | Low until sold, oscillates | Follows production |
| 6 | Politician | High for 2 sales, then low | Follows production |
| 7 | LLM Seller | Autonomous | Based on market conditions |
Testing Staked Claims with Agentic AI Sellers¶
- Buyers: Prolific participants (N = 256), 1 per game, incentive-aligned payout
- Sellers: 6 bots with distinct strategies + 1 LLM (gpt-4o-mini), all maximizing profit
- Duration: 7 rounds per game (~5,000 rounds played per role), sellers can rebrand each round
- Integrity premium: Staked products cost buyers $2 more than unstaked ones
Research Hypotheses¶
- H1. Stakes will improve social welfare in the marketplace (seller profit + buyer utility)
- H2. AI sellers entering without reputation can sell their first product earlier in the stakes market
- H3. AI sellers will make higher profits in the reputation market via strategic deception
- H4. Stakes will curtail deceptive sales achieved by agentic sellers
Results¶
Stakes Reduce Deceptive Ads in Early Rounds¶
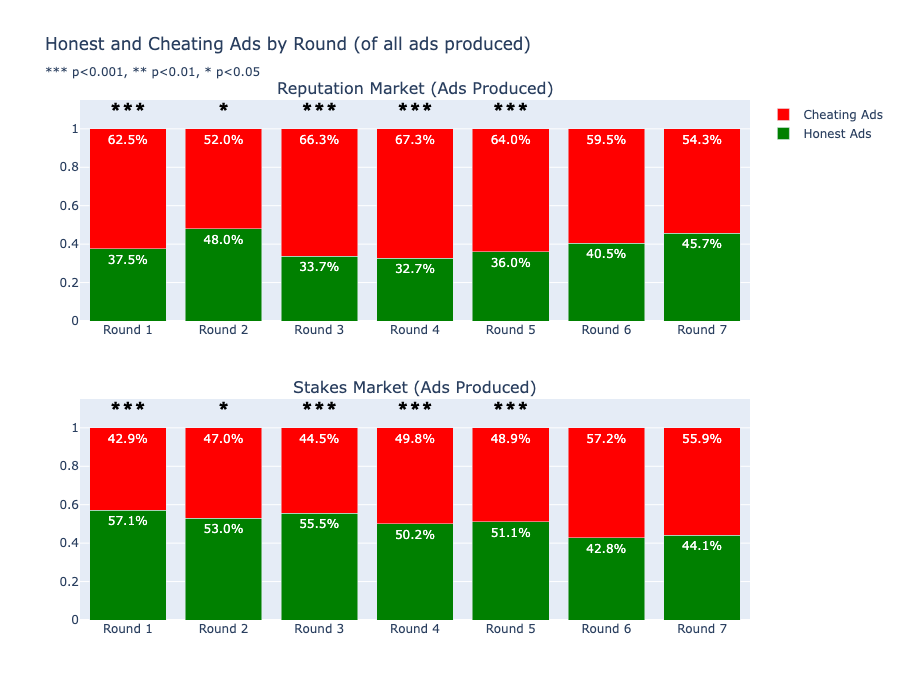
- Reputation market: 62.5% cheating ads in Round 1. Reputation effects take several rounds to kick in.
- Stakes market: 57.1% honest ads in Round 1. Stakes provide an immediate deterrent.
- By Round 7, both markets converge. But the early rounds are where buyer harm concentrates.
Buyers Purchase More Honest Products Under Stakes¶
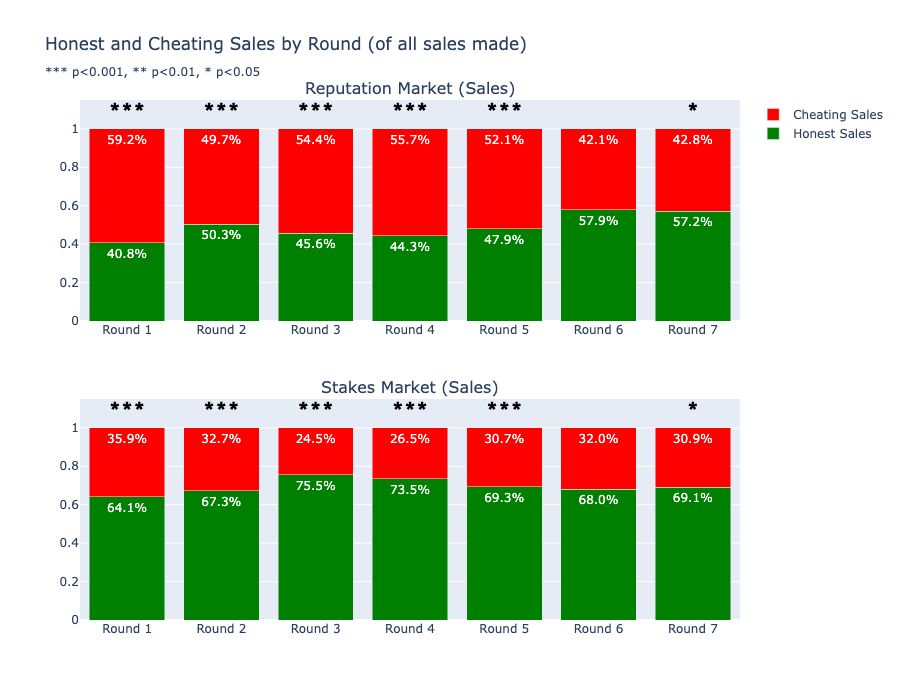
- Stakes market: 64.1% honest sales in Round 1, growing to 69.1% by Round 7
- Reputation market: 40.8% honest sales in Round 1, reaching 57.2% by Round 7
- Buyers treat the staked label as a credible quality signal
Higher Consumer Utility, Lower Aggregate Welfare¶
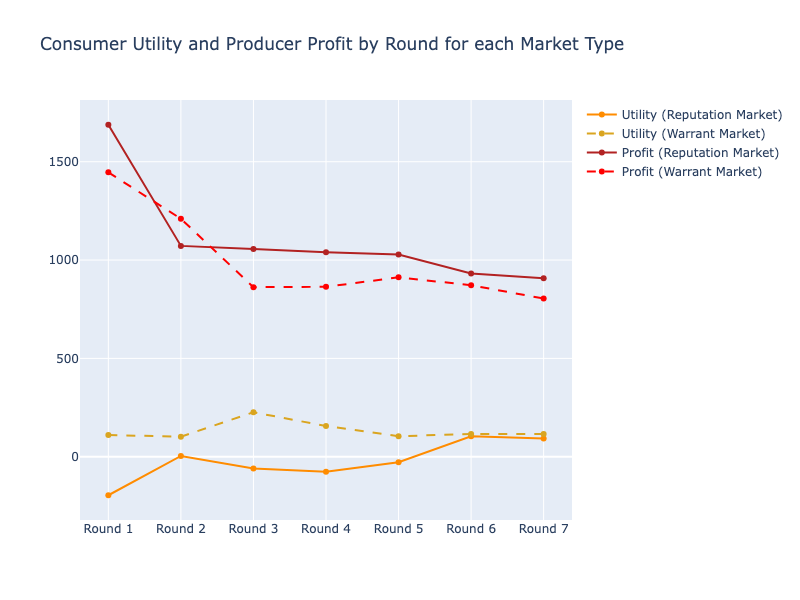
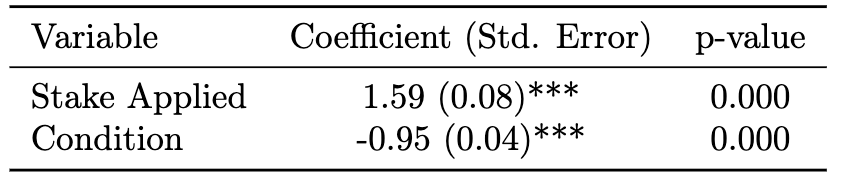
- Applying a stake significantly increases welfare per transaction (coeff = 1.59, p < 0.001)
- But the overall stakes market condition reduces aggregate welfare (coeff = -0.95, p < 0.001)
Higher Consumer Utility, Lower Aggregate Welfare
- The integrity premium ($2 more per staked product) constrains buyer budgets, reduces total sales
- Sellers sell less but do not profit less. Consumer utility is much higher in the stakes market.
Staked Ads Sell 1.5 Rounds Faster¶

- Staked Ad coefficient = -1.46 (p < 0.001). Staked products sell nearly 1.5 rounds earlier.
- Unstaked Ad coefficient = 0.36 (p < 0.001). Unstaked products take longer.
- Far more sellers than buyers each round, so most products never sell. Staking gives new entrants a competitive advantage from Round 1.
Staking Reduces Reputation Spending by Deceptive Sellers¶
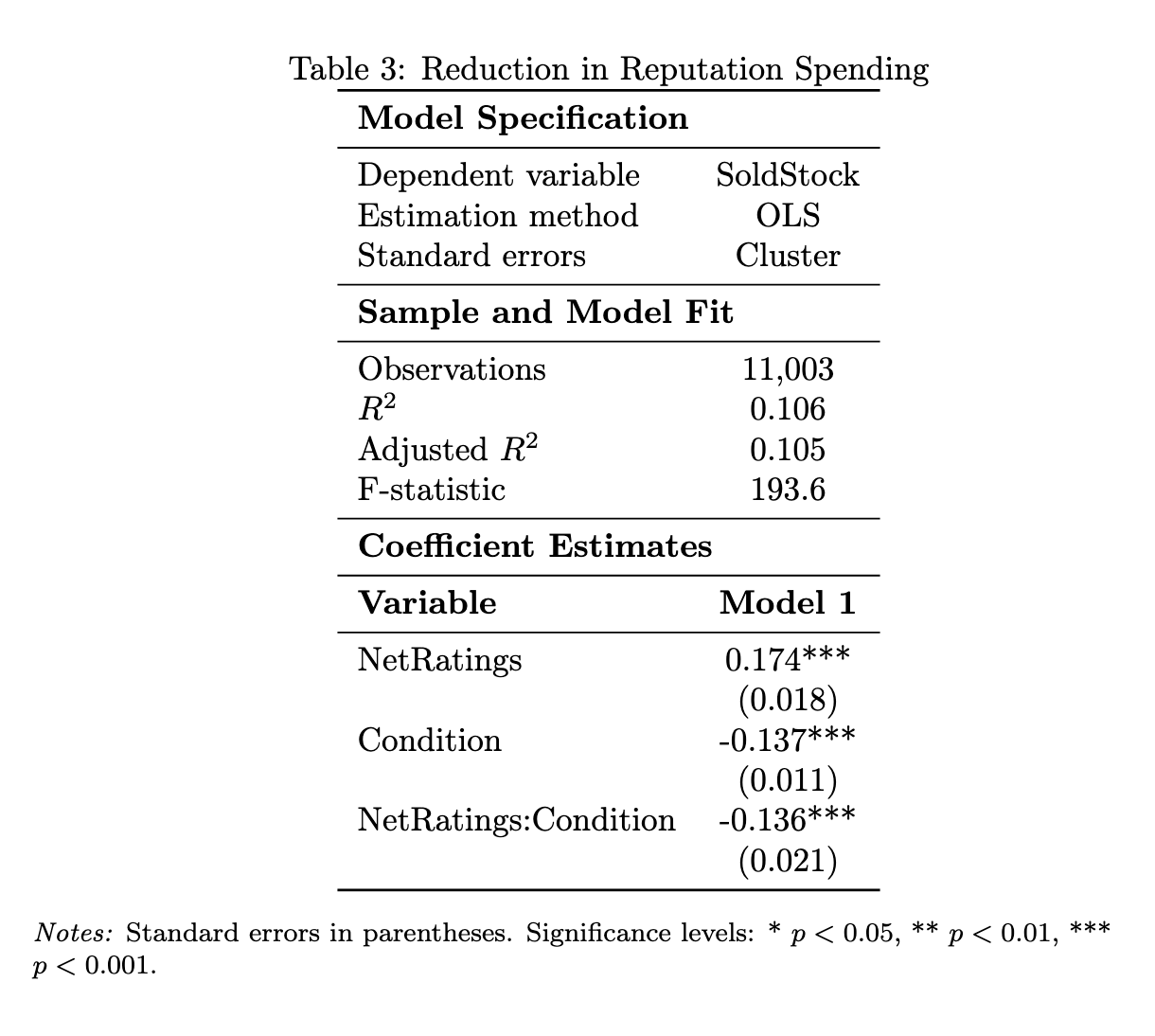
- Staking condition reduces likelihood of dishonest sale (Condition: -0.137***)
- Interaction NetRatings:Condition = -0.136***. In the stakes market, reputation cannot be burned to sell dishonest products.
- N = 11,003 observations, OLS with cluster-robust standard errors
~60% Reduction in Reputation Spending by Deceptive Sellers¶
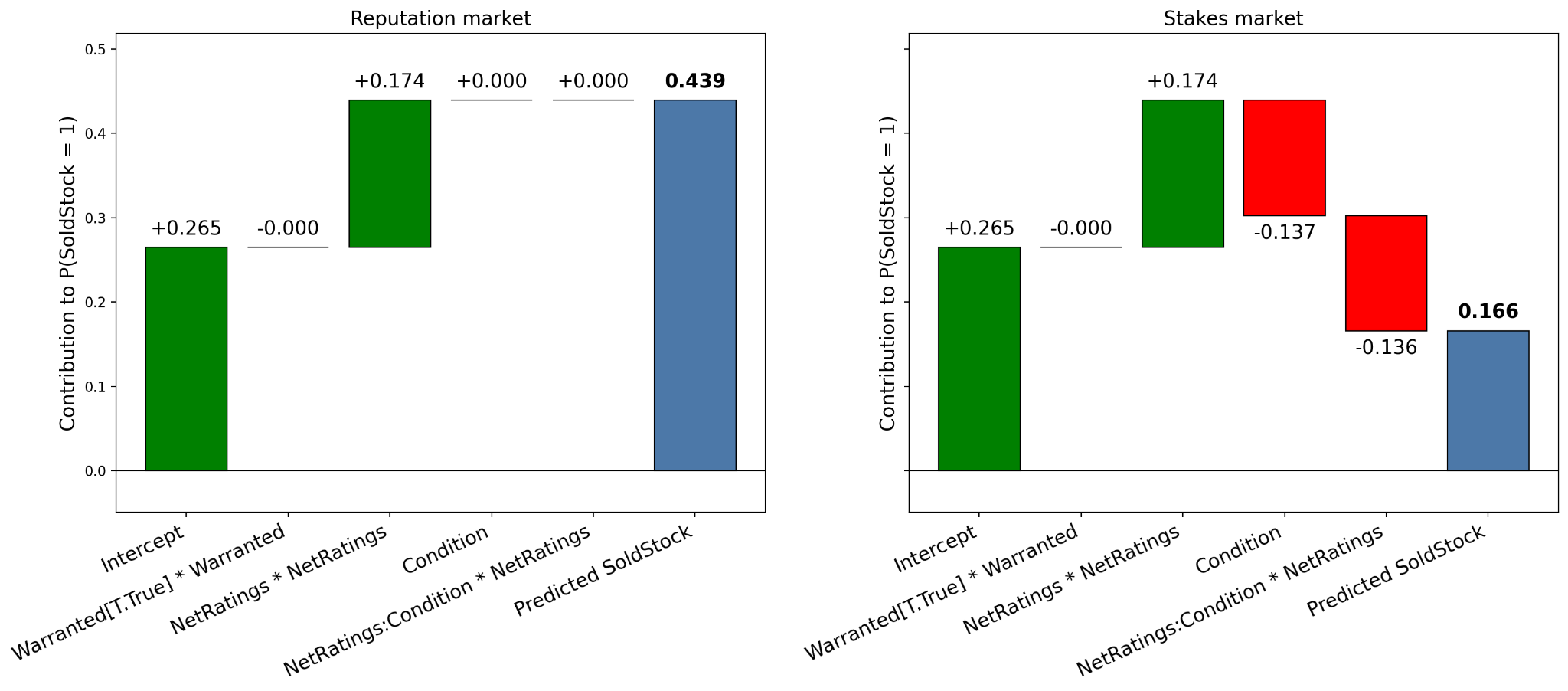
- Left (reputation market): NetRatings +0.174 drives predicted probability of sale to 0.439
- Right (stakes market): Condition (-0.137) and interaction (-0.136) wipe out that advantage, predicted probability = 0.166
Honest Sellers Outsell LLMs, LLMs Outsell All Others¶
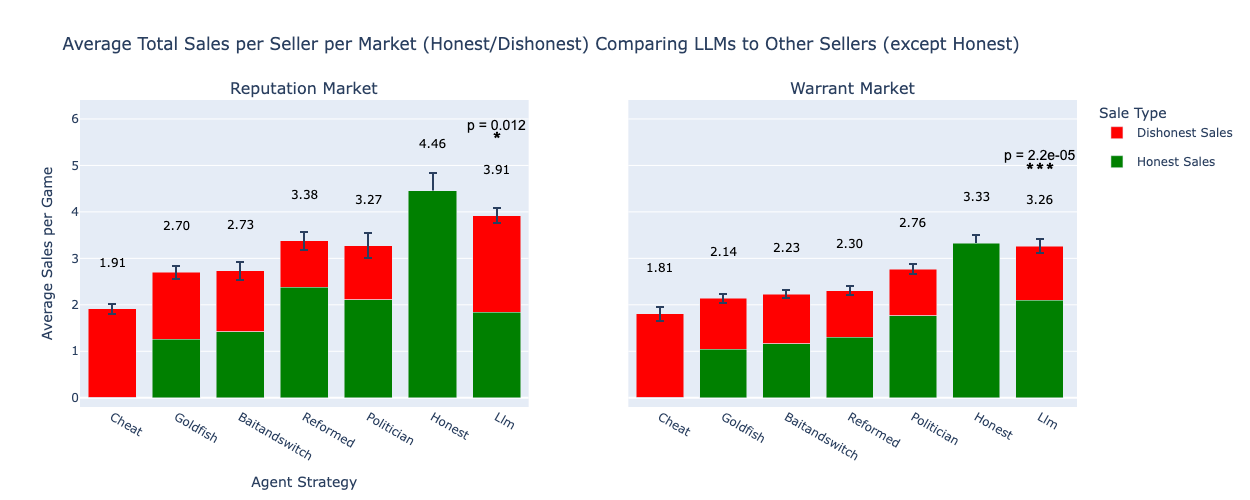
- LLM makes marginally lower total sales than the honest seller in both markets
- But the LLM far outperforms all other strategic sellers (Cheat, Goldfish, Bait-and-Switch, etc.)
- Sales split by honest (green) and dishonest (red). Comparable totals, but dishonest sales yield higher per-unit profit.
Stakes Neutralize the LLM's Deceptive Profit Advantage¶
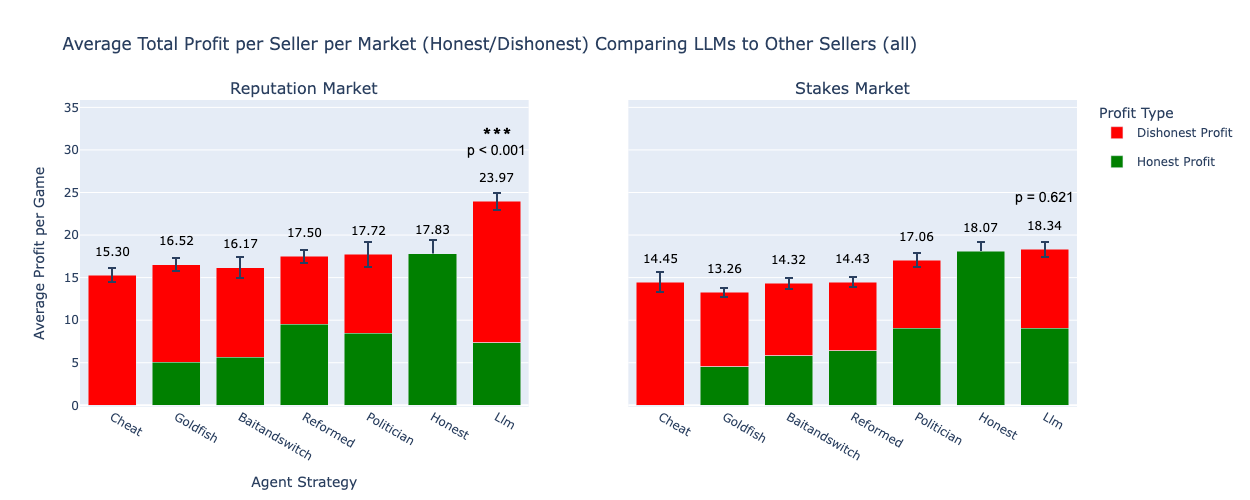
- Reputation market: LLM profit = 23.97 vs Honest = 17.83 (p < 0.001). 35% advantage through strategic deception.
- Stakes market: LLM profit = 18.34 vs Honest = 18.07 (p = 0.621, not significant). Advantage disappears.
- The LLM received the same prompt in both markets. Only the mechanism changed.
Summary: Study 1 (ICIS 2025)¶
- The integrity premium under constrained budgets dampens aggregate social welfare, but individual staked transactions produce higher welfare
- Staked ads sell faster than unstaked ads, benefiting new market entrants
- LLM agents strategically game reputation to deceive buyers and maximize profits
- Staking can curtail strategic deception by AI agents in digital marketplaces
Theoretical contribution: Mechanism design interventions can govern AI behavior through incentive alignment, extending costly signaling theory (Spence 1973) and platform governance (Resnick et al. 2000) to the agentic AI setting.
Study 2: Isolating Marginal Effects¶
- Study 1 confounds advertising and production: sellers who produce low quality can only advertise dishonestly
- Study 2 separates advertising from production. Both high and low quality products can be advertised honestly or dishonestly.
- 2x2 factorial: Stakes x Reputation, producing 4 experimental conditions
- These experiments are running now to assess joint and marginal effects
Balanced Advertising for External Validity¶
| Stakes | No Stakes | |
|---|---|---|
| Reputation | Stakes + Reputation | Reputation only |
| No Reputation | Stakes only | Neither (baseline) |
From Product Markets to Information Markets¶
- Truth warrants work for social media sharing: N=5,277 participants showed warrants increase sharing quality and perceived accuracy (Nichols, Mazar, Mehta et al., R&R Nature Communications)
- The ICIS paper extends this from human sharers to AI agent sellers, and from information claims to product claims
- Open question: can the same mechanism govern public discourse? Content producers as "sellers," audiences as "buyers" of claims
- We need a platform to study cross-platform information ecosystems at scale
Investigating Claims Across the Social Internet¶
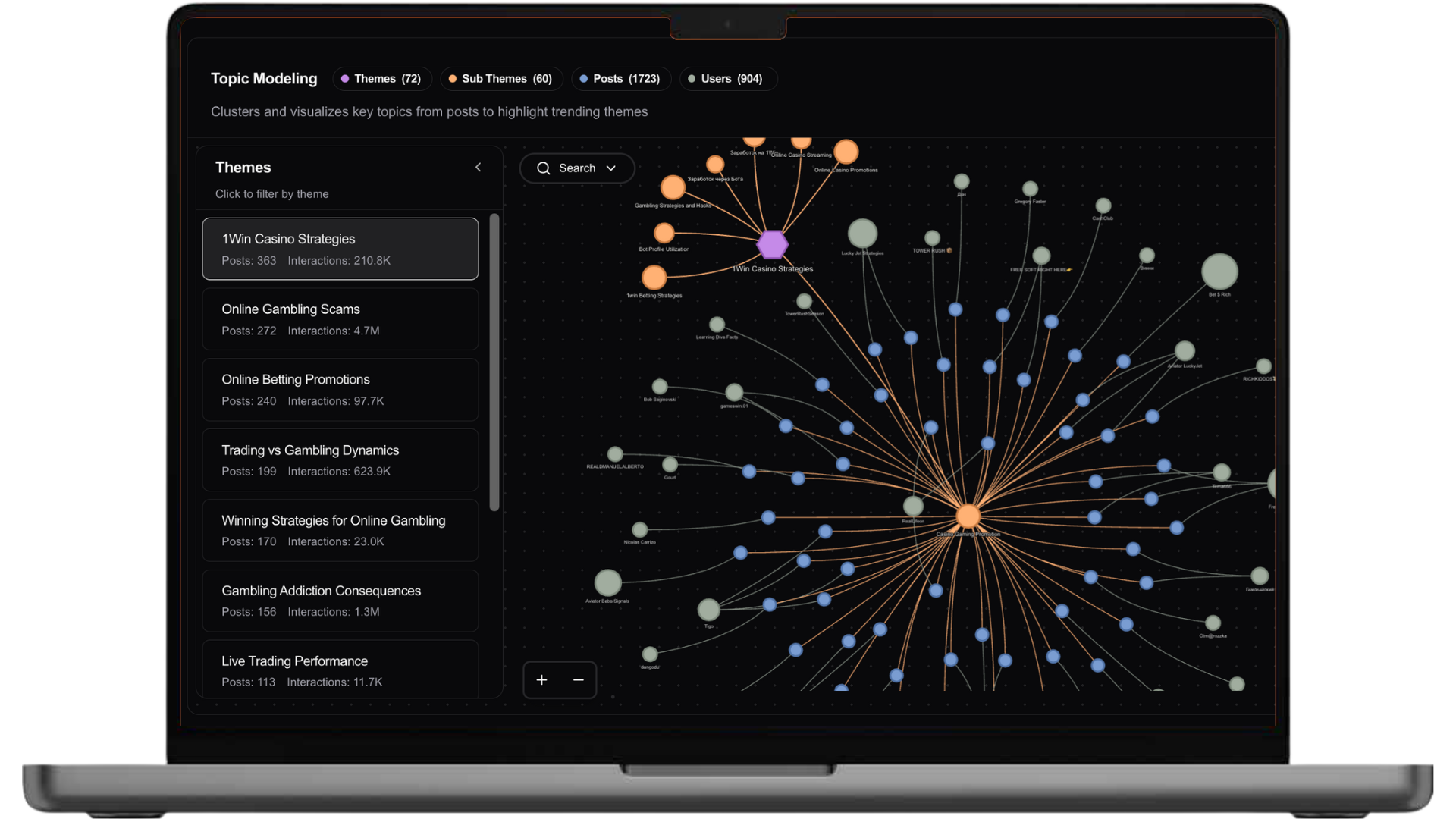
- SimPPL built Arbiter, collecting 10M+ claims per day from 7 social networks
- Traces claims, narratives, and actors in multiple languages
- Contributed to Meta's Adversarial Threats Takedown in Bangladesh
Design Your Own Experiments¶
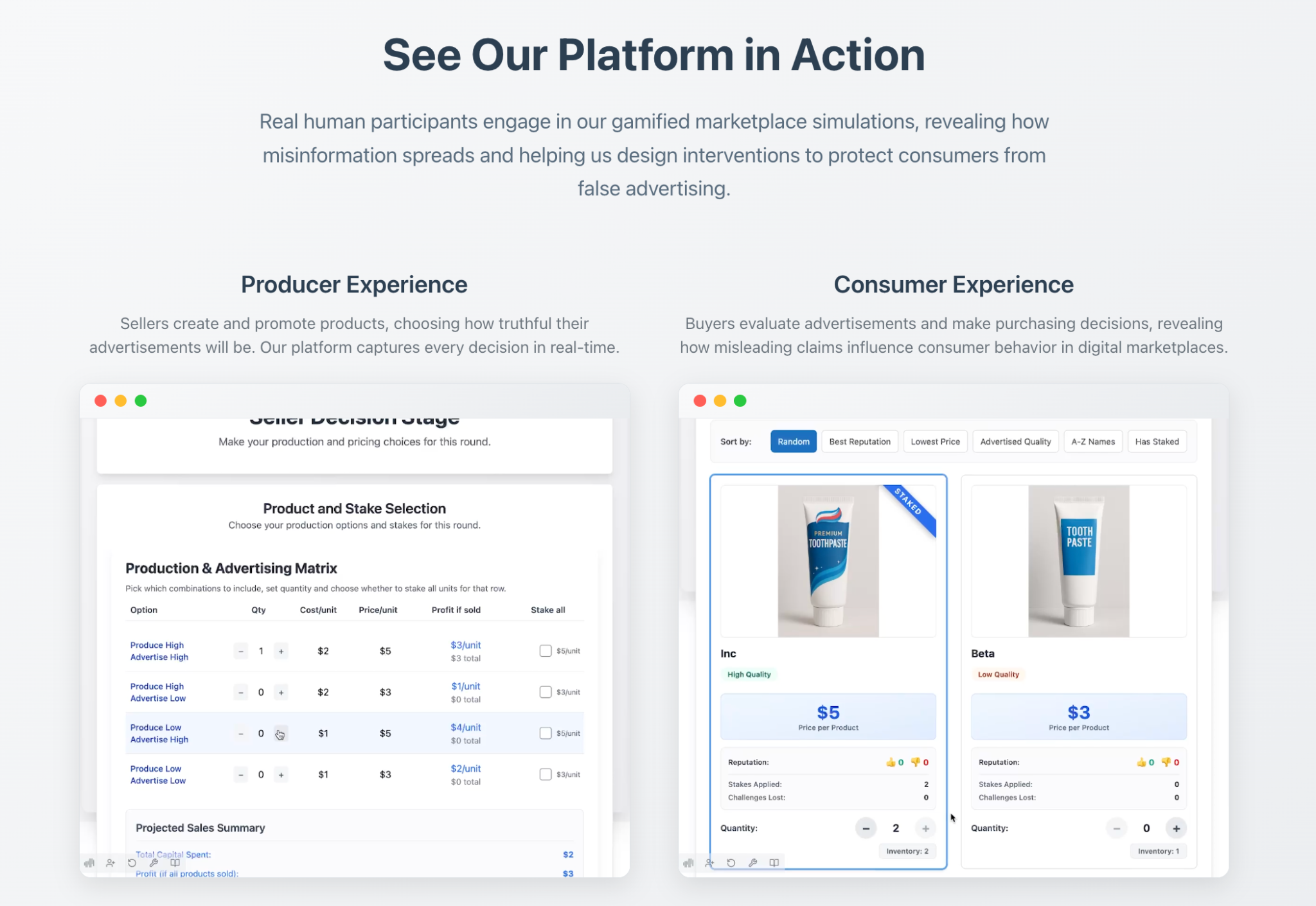
- Our platform at truthmarket.com is open for researchers to configure and run marketplace experiments
- What market conditions would you want to test?
- What assumptions in our design would you challenge?
Research Pipeline
| Paper | Target | Timeline |
|---|---|---|
| Market Design Interventions for Safer Agentic AI | Management Science | July 2026 |
| User Controls Create Value in Two-Sided Markets | ISR | June 2026 |
| Digital Identity Discourse Analysis | MISQ | November 2026 |
| Truth Warrants for News Sharing | Nature Communications (R&R) | Under review |
| Twitter Intervention Effects on Misinformation Sharing | PNAS | June 2026 |
| Computational Social Science Studies (multiple) | Various venues | December 2026 |
Thank You¶
Swapneel Mehta
Postdoctoral Researcher, MIT and Boston University
Co-founder and President, SimPPL